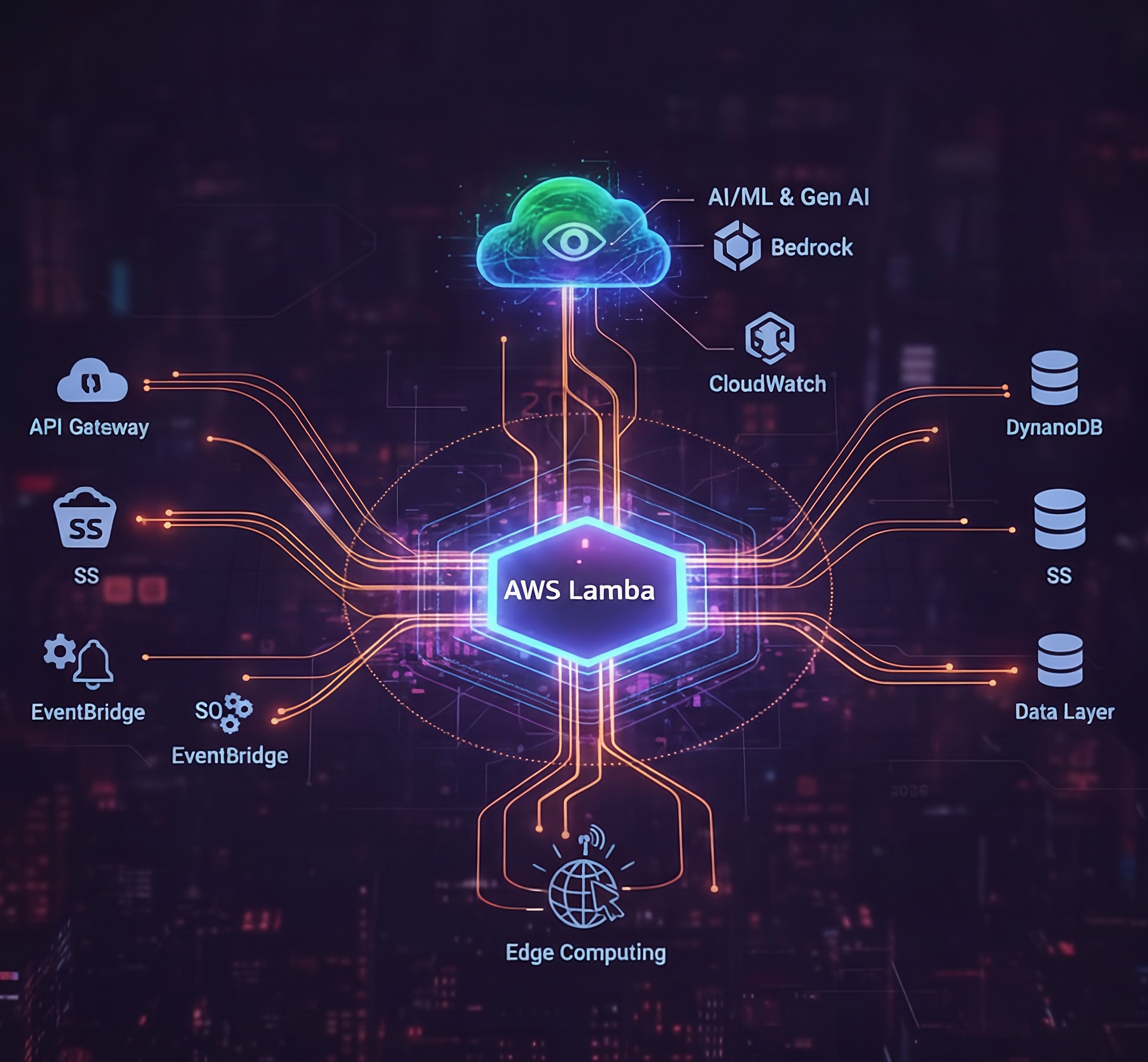
AWS Lambda and serverless computing have shifted from being an "alternative" to the default architectural standard for scalable enterprise applications. The market is projected to grow from $21.9 billion in 2024 to over $44 billion by 2029, driven by a massive integration of AI and edge computing.
Architecture
Typical Lambda-based backend: API Gateway + event sources (S3, DynamoDB, SNS, SQS, EventBridge) + Lambda + data layer (DynamoDB/S3) + CloudWatch.
Standard serverless backend pattern showing Lambda as the central compute layer. Multiple event sources (S3, DynamoDB streams, SNS, SQS, EventBridge) trigger functions asynchronously, while API Gateway handles synchronous requests. The data layer uses DynamoDB for NoSQL and S3 for object storage, with CloudWatch providing comprehensive observability.
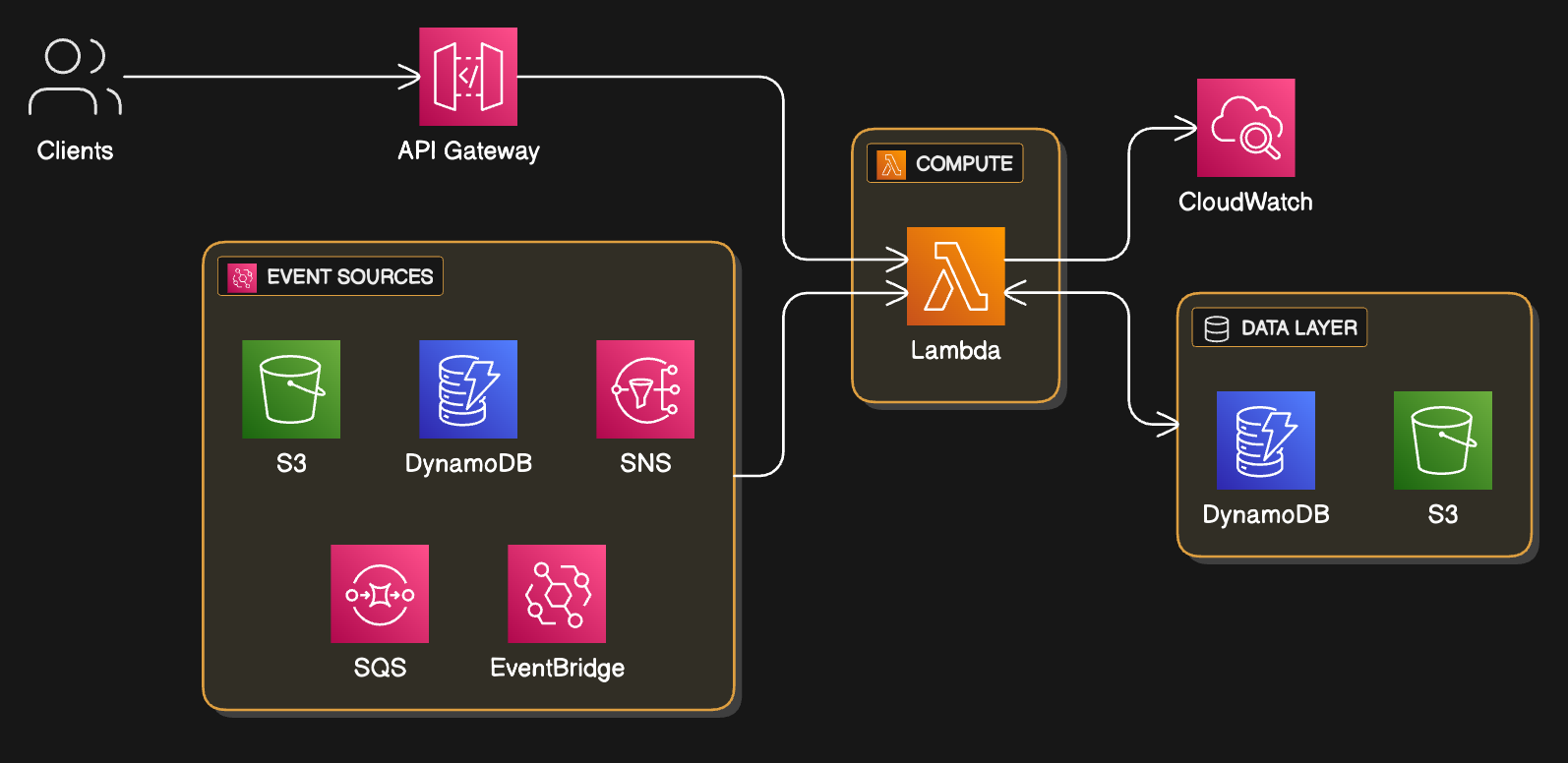
- Clients call API Gateway, which routes requests to Lambda functions.
- Event sources like S3, DynamoDB streams, SNS, SQS, and EventBridge asynchronously trigger the same or other functions.
- Lambda reads/writes to DynamoDB and S3 as the primary data layer and emits logs/metrics to CloudWatch for observability.
What is AWS Lambda?It is a serverless compute service that lets us run code without provisioning servers and automatically manages scaling, patching, and high availability. Developers upload code (or container images), configure triggers (API Gateway, EventBridge, S3, DynamoDB, Kafka, etc.), and only pay for execution time and resources used. Newer capabilities include features like SnapStart for more runtimes, improved cold‑start behavior, better monitoring through CloudWatch Application Signals, and real‑time log streaming via Live Tail.

Why is AWS Lambda in high demand?
1. Serverless + AI/ML and Gen AI
- Organizations increasingly use serverless to host ML inference and LLM-powered features because it scales with unpredictable traffic and removes infra overhead.
- Lambda fits naturally into generative AI architectures for orchestrating LLM calls, pre/post-processing, and event-driven workflows, especially with AWS-provided AI services.
- RAG Pipelines: Retrieval-Augmented Generation (RAG) relies heavily on serverless to fetch context from vector databases and feed it into models securely and quickly.
 API Gateway → Lambda → Bedrock/LLM → Lambda post‑processor → EventBridge/SQS -> downstream services.
API Gateway → Lambda → Bedrock/LLM → Lambda post‑processor → EventBridge/SQS -> downstream services.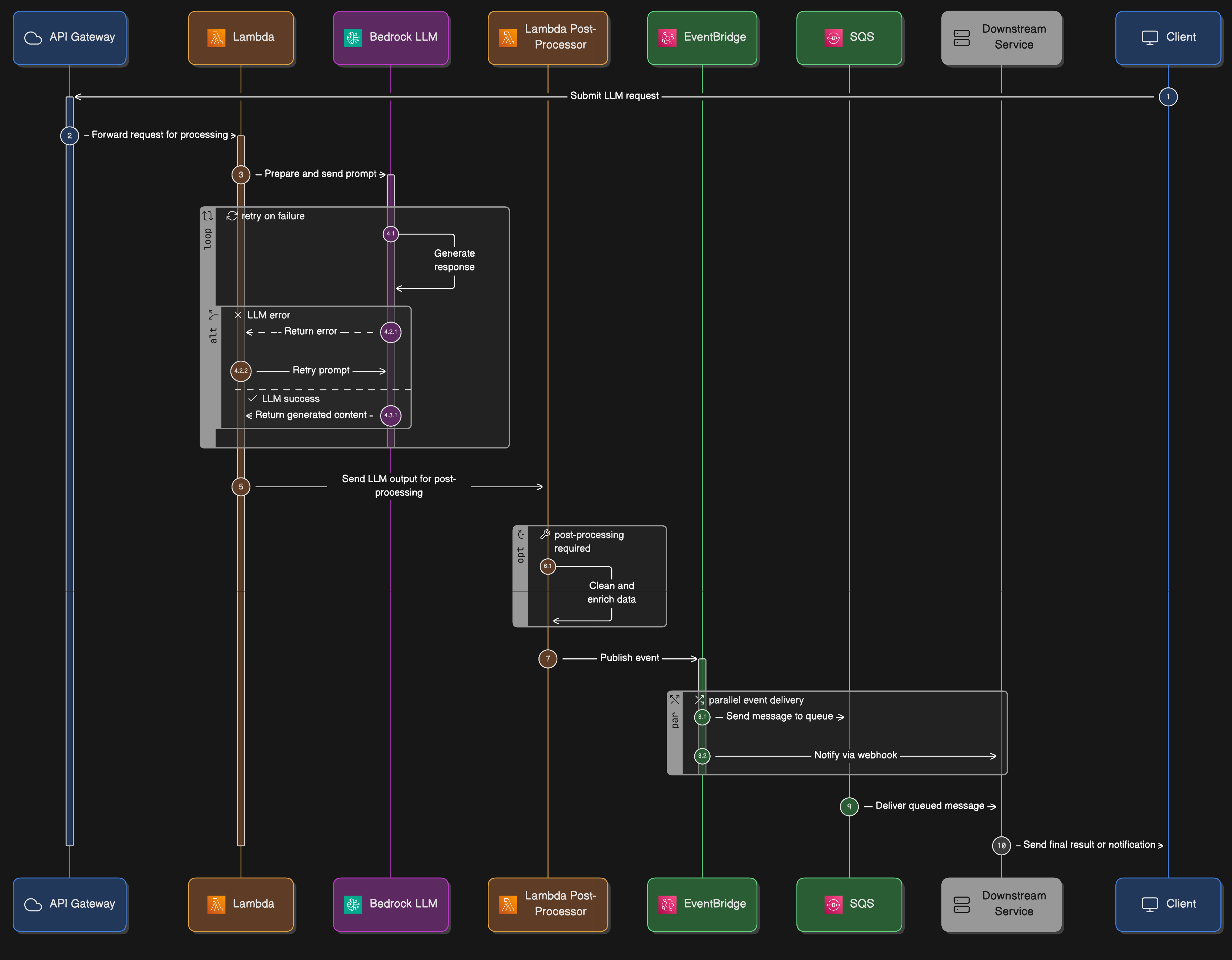
Event-driven AI workflow demonstrating serverless RAG (Retrieval-Augmented Generation) architecture. Shows complete flow from API Gateway through Lambda orchestration, Bedrock LLM integration, post-processing, and downstream event distribution. This pattern handles unpredictable AI workload spikes while maintaining cost efficiency.
2. Edge and low-latency experiences
- Edge serverless (Lambda@Edge, CloudFront Functions, Cloudflare Workers) brings compute closer to users and supports real-time applications and security checks with minimal latency.
3. Enterprise workloads and complex pipelines
- Serverless has moved from “nice for side projects” to powering core enterprise workloads like transaction processing, fraud detection, and healthcare telemetry.
4. Multi-cloud and portability
- Teams are experimenting with multi-cloud serverless strategies, either via frameworks (Serverless Framework, SAM) or portable platforms like Knative.
- The goal is to reduce vendor lock‑in for business-critical workloads while still using Lambda where AWS is the strongest.
5. Performance Optimization Strategies
Cold Start MitigationModern serverless architectures address cold start challenges through:
- Provisioned Concurrency: Pre-warmed function instances for latency-critical applications
- Connection Pooling: Reusing database connections across function invocations
- Lightweight Runtimes: Optimized runtime environments for faster initialization
6. Security in Serverless Architectures
Zero-Trust Security ModelServerless architectures naturally align with zero-trust security principles:
- Function-Level Permissions: Each function has minimal required permissions
- Network Isolation: Functions operate in isolated execution environments
- Encryption at Rest and Transit: All data encrypted by default
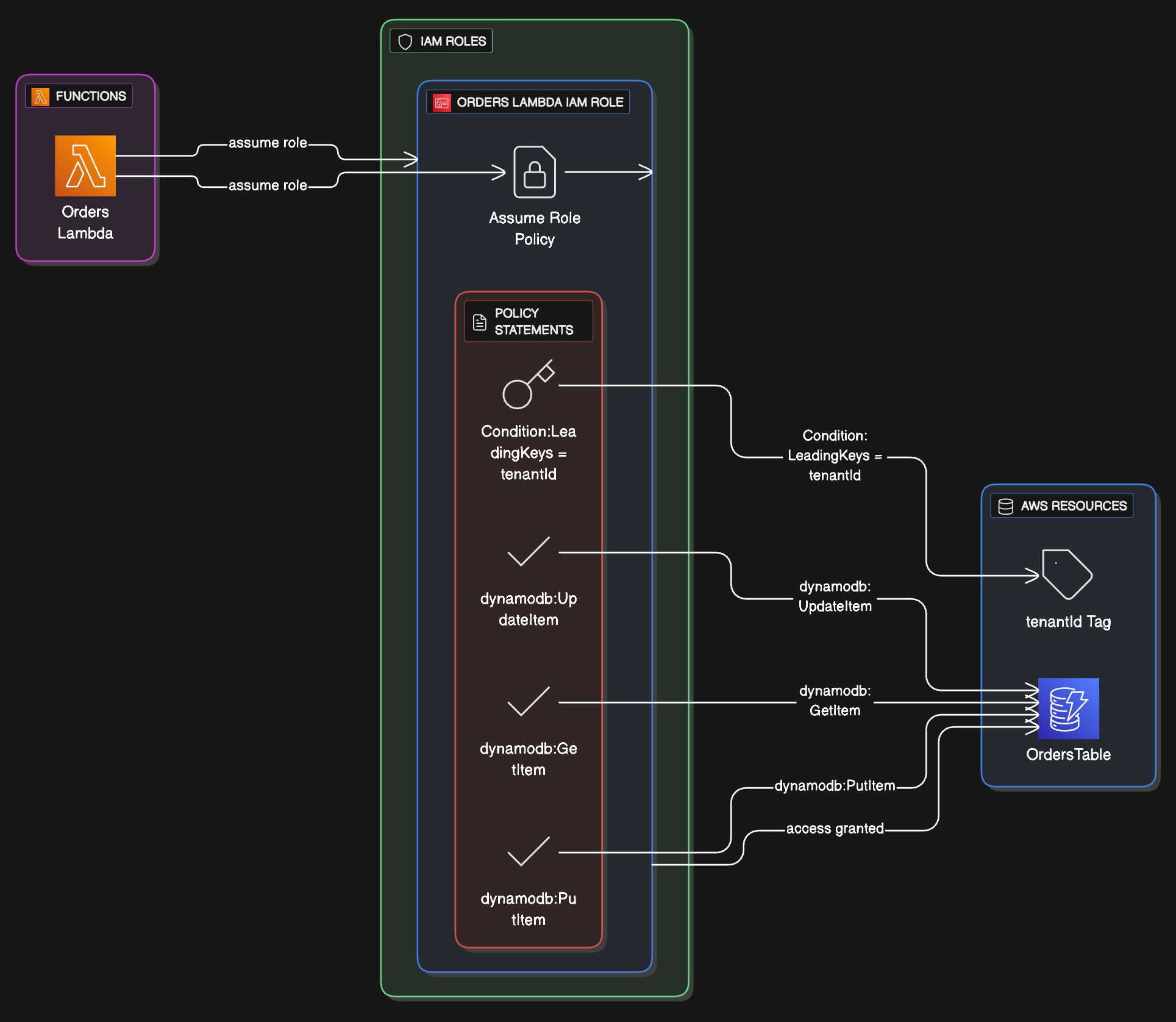
Each function should get a focused IAM role with only the actions and resources it really needs. For example, a Lambda that owns a single DynamoDB table might use a policy like this:
Identity and Access Management

Zero-trust security model showing Lambda function with least-privilege IAM role. The policy demonstrates condition-based access control using tenant isolation via DynamoDB LeadingKeys, ensuring each function can only access data belonging to its assigned tenant. This pattern is essential for multi-tenant SaaS applications.
 7. Cost Optimization and FinOps
7. Cost Optimization and FinOps
Serverless Cost ManagementOrganizations implement sophisticated cost optimization strategies:
- Right-Sizing: Continuous optimization of memory allocation based on actual usage
- Scheduling: Time-based scaling for predictable workloads
- Multi-Cloud Strategy: Leveraging different providers for cost optimization
FinOps right‑sizing and provisioned concurrency

Use Cases
- Event-driven backends: API endpoints, webhooks, and microservices that react to events from S3, DynamoDB, SQS, Kafka, or EventBridge.
- Real-time data and IoT: sensor processing, streaming analytics, anomaly detection, and notification pipelines.
- AI-powered features: chatbots, recommendation engines, document processing, and real‑time personalization integrated with AI/ML services.
- Automation and scheduled jobs: backups, report generation, ETL pipelines, and DevOps automation via scheduled triggers.
Why is leadership betting on serverless?
- Faster time to market: No server provisioning or patching means teams can ship features quickly, which is especially critical for startups and product-led growth models.
- Built-in scalability and resilience: Functions automatically scale across availability zones, handling 10–50x spikes without manual intervention.
- Cost efficiency: For spiky or unpredictable workloads, companies often report up to ~70% cost savings when shifting from always-on instances to Lambda.
Trade-offs and challengesVendor lock-in and skill gaps: Deep integration with AWS services increases dependency on a single provider, and teams need to invest in serverless-specific skills and patterns:
Observability and debugging complexity: Distributed, event-driven flows increase the need for structured logging, tracing, and strong governance around function sprawl.
- Request Tracing: End-to-end request tracking across multiple functions Performance Monitoring:
- Real-time performance metrics and alerting Error Tracking: Comprehensive error logging and analysis
To make those tools useful, every function should emit structured, context‑rich logs with a trace id. Here is a lightweight pattern:

Conclusion
The serverless revolution represents a fundamental shift in enterprise architecture. AWS Lambda and serverless computing have evolved from experimental technologies to the default standard for scalable, cost-effective applications. The convergence with AI and edge computing has accelerated adoption, making serverless-first architectures the norm rather than the exception.
As we move forward, serverless architectures will continue evolving, incorporating emerging technologies like quantum computing, advanced AI capabilities, and edge-cloud integration. The question for enterprises is no longer whether to adopt serverless, but how quickly they can transform their architectures to leverage its full potential.
Happy Learning!